#stack : 컬럼 레벨에서 인덱스 레벨로 데이터프레임을 변경합니다.
#unstack : 인덱스 레벨에서 컬럼 레벨로 데이터프레임을 변경합니다.
pivot = pd.pivot_table(df, index=['Sex','Pclass'], values=['Survived','Fare'], aggfunc=['mean','median','sum'])
pivot
.stack(숫자, future_stack=True) #숫자만 쓰는것은 나중에 없어질 예정이라, future_stack=True를 꼭 같이 써주자.
pivot.stack(0, future_stack=True) #컬럼의 첫번째 레벨을 인덱스로 내립니다.
#0대신 1쓰면 두번째 레벨을 인덱스로 내림
.unstack(숫자)
pivot.unstack(1) #인덱스의 두번째 레벨을 컬럼으로 쌓아 올립니다
.melt(col_name, id_vars = 기준컬럼) #wide dataframe을 long dataframe으로 변경하는 함수

#예시 dataframe
data = pd.DataFrame({'name':['a','b','c']
, 'order_count':[3,4,10]
, 'amount':[10000,25000,300000]})
pd.melt(data, id_vars=['name'])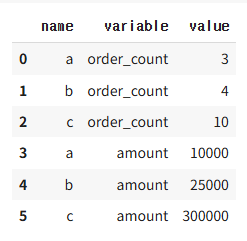
여기서 variable, value 의 이름을 바꾸고 싶다면
pd.melt(data, id_vars=['name'], var_name='type', value_name='val')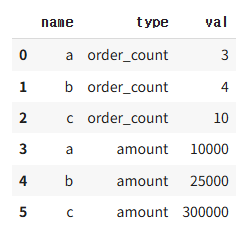
'Python_Wiki > Python_Library' 카테고리의 다른 글
| matplotlib / seaborn 한글 적용하기 (0) | 2025.07.14 |
|---|---|
| Seaborn 스타일 설정 (2) | 2025.07.14 |
| pandas: 피벗테이블 만들기 .pivot_table /+) pivot (0) | 2025.07.14 |
| pandas: crosstab / 범주형 데이터 비교 분석 (0) | 2025.07.14 |
| pandas - 데이터 결합: join(파이썬) / merge / concat (1) | 2025.07.14 |

